쇼핑몰 고객 그룹 나누기
- 고객의 성별, 나이, 연 수입과 소비 점수의 데이터를 가지고 Clustering을 해 본다.
칼럼 중 'Customer ID'는 고객 특성을 나누는데 의미 있는 자료가 아니므로 Role을 'skip'으러 변경한다.

Clustering
- File에서 오른쪽으로 선을 그어 뺀 후 선택창에서 'k-Means' 아이콘을 선택한다.
- k-Means는 Clustering에서 자주 사용하는 대표적인 모델이다.
- k-Means의 k는 임의의 값으로 분석가가 원하는 숫자를 말하면 그에 맞춰서 그룹 개수를 만들어 준다.
- Cluster의 수를 From~to를 선택하면 해당 범위에서 가장 가장 적절한 그룹 개수를 알려준다.
- Silhoutte Scores가 1에 가까울수록 적절하다는 뜻이므로 6개로 나누는 것이 가장 적절해 보인다.


- 총 6개의 그룹으로 나누어진 것을 볼 수 있다.
시각화
- Scatter Plot으로 시각화를 해 보자.
- 먼저 x축과 y축을 각각 Age와 Annual Income(k$)로 지정한다. 어차피 나중에 변경할 것이다.
- Color를 Cluster로 변경하여 6개의 클러스터가 각각 다른 색상으로 표시되도록 한다.
- 잘 그룹화 되어 있지 않다면 Informative Projections 버튼을 클릭한 후 아래쪽에 있는 Start 버튼을 누른다.
- 아래 그림과 같이 Annual Income(연간 소득)과 Spending(소비수준) 을 기준으로 나누면 좋을 것 같다고 인공지능이 제안해 준다.

- 인공지능의 제안대로 X축은 연간 소득, Y축은 소비 수준으로 두니 깔끔라게 그룹이 구분되었다.

Recluster
- k-Means에서 오른쪽 아래로 선을 그어 Box Plot을 불러오자.
- Subgroups을 Cluster로 변경한다.
- Variable들을 순서대로 클릭해 보면 그에 맞는 정보가 오른쪽에 나타난다.
- Age를 선택하면 인공지능이 C2와 C7을 구분하였는지 알 수 있다. C2는 주로 50대이고 C7은 20대인 것을 알 수 있다.

다차원 척도법(MDS:multidimensional scaling)
- C2와 C7 클러스터가 잘 구분되어 보인다.
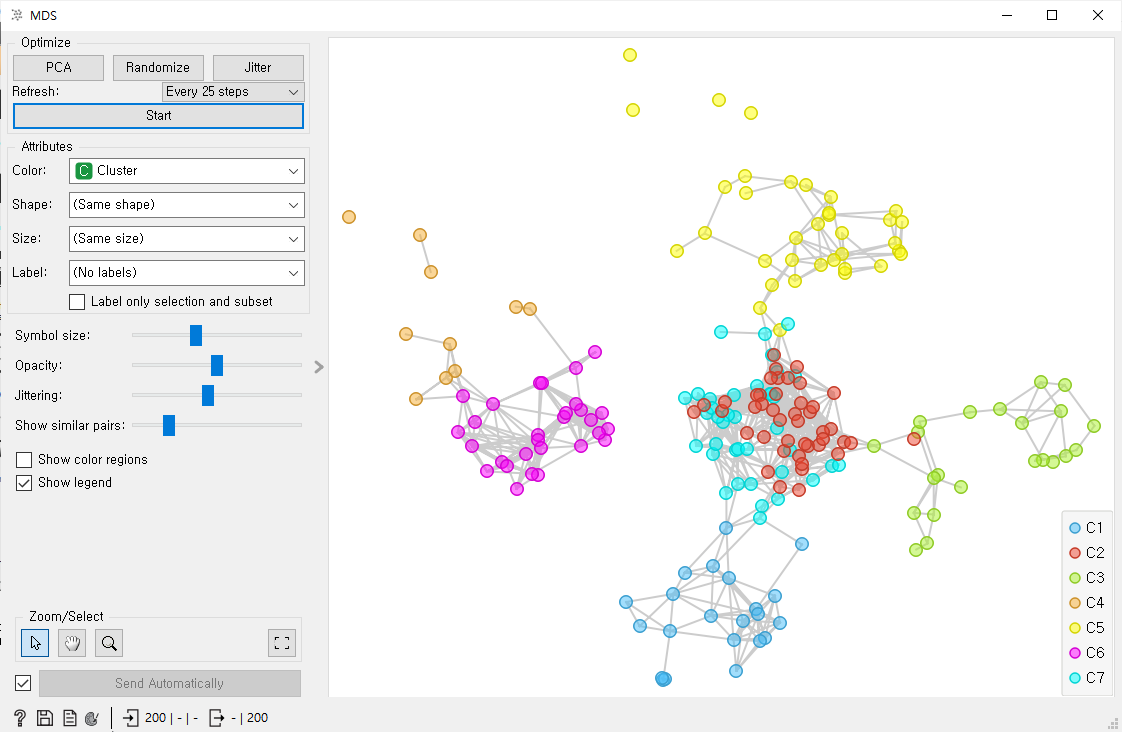
- k-Means에서 Linear Projection을 불러온다.
- Color을 Cluster로 변경하고 Suggeust Features를 클릭 후 새로 뜬 창에서 Start 버튼을 누른다.
- Number of Variables의 변수를 3개에서 4개로 변경하면 4개 변수를 모두 고려한 분포가 나타난다.

'WEB + AI실무프로젝트 > Orange3 실무 프로젝트' 카테고리의 다른 글
| 5. 개, 고양이, 호랑이 구분하기 (0) | 2021.08.11 |
|---|---|
| 3. 아이오와 집값 예측하기 (0) | 2021.08.11 |
| 2. CT 사진으로 암 진단하기 (0) | 2021.08.11 |
| 1. 이직할 직원 예측하기 (0) | 2021.08.11 |